Predicting&Training
1. Introduction to Yolo v8
Continuing from the previous article, Yolo v8 offers two modes of operation: you can write and execute a Python file yourself, or use the Command Line Interface (CLI). Here, we will unify the process by operating through the Terminal.
Open the terminal:
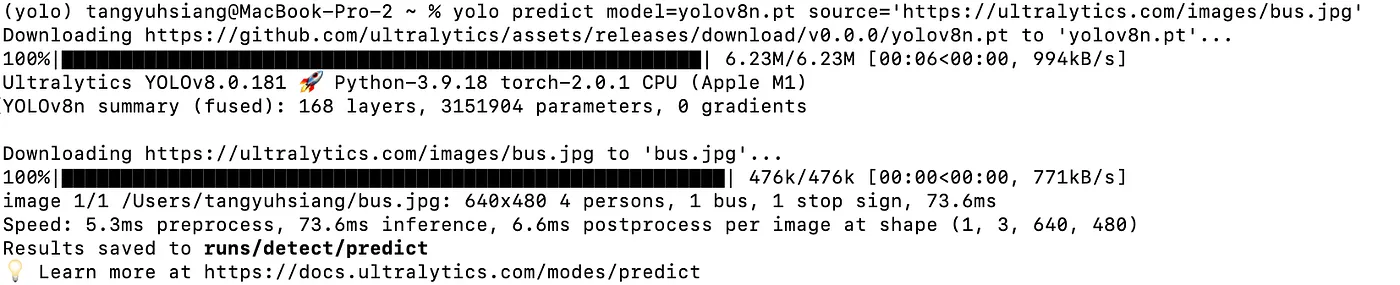
yolo predict model=yolov8n.pt source='https://ultralytics.com/images/bus.jpg'
2. Setting Up for Prediction
Here, it will download an image file named 'bus.jpg' from the official website to your computer. Then, it will use the yolov8n model to predict (predict) the contents of this image. The results of the prediction will be stored in the 'runs/detect/predict' directory (by default, this will be in your user-level folder).
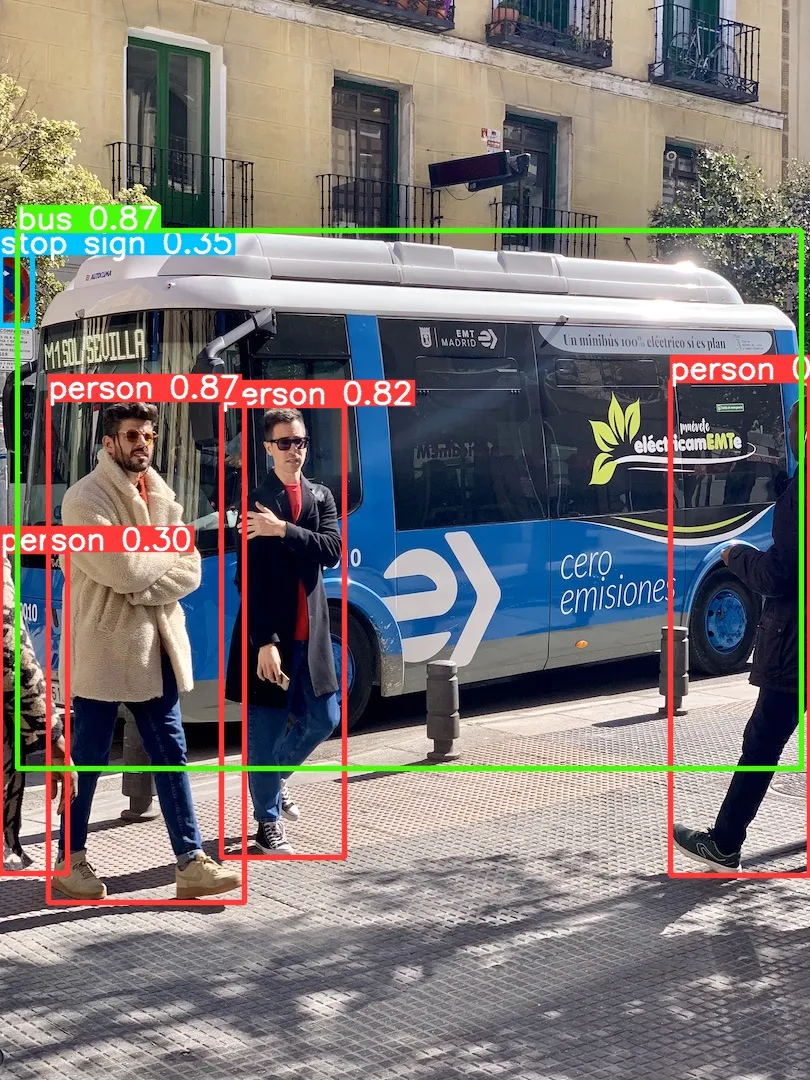
Original Image:

The results predicted by Yolov8n:
Below are the types of models trained using Yolo, totaling 5 varieties:
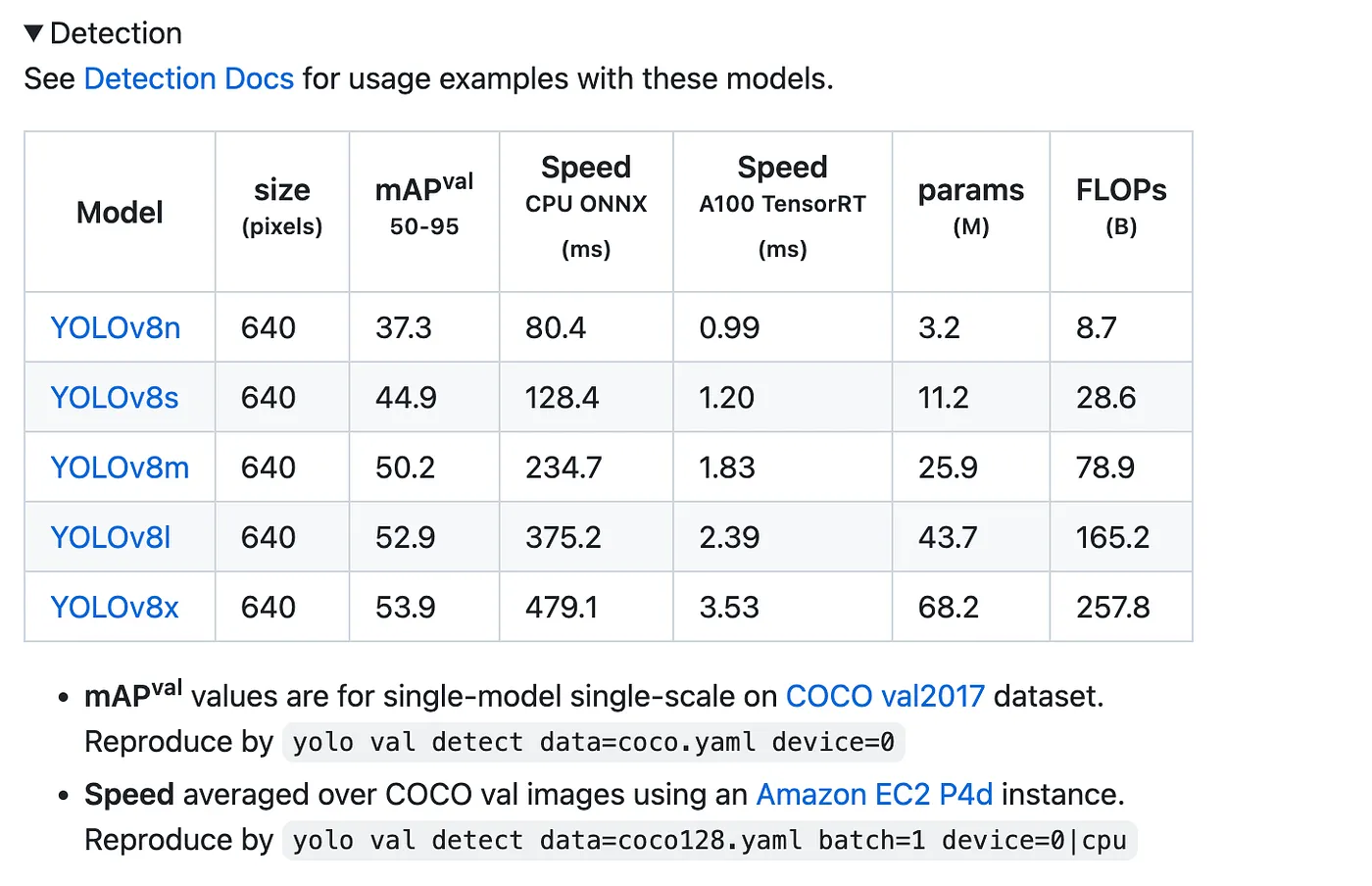
For lighter training, you can choose YOLOv8n as the training model. This concludes the basic image prediction with Yolo.
3. Training the Yolo Model
Next, we will proceed with image model training, which is the well-known machine learning (Machine Learning). We aim to train our model to increase the accuracy of object detection to meet our expectations.
The official training file is 'coco.yaml'. Click here to view the official document file. Here, we use their trained yaml file as an example for our training.
Model training can be done using CPU, GPU, or M1 chips. Please enter the following command in the terminal:
For CPU training:
yolo detect train data=coco128.yaml model=yolov8n.pt epochs=100 imgsz=640 device=cpu
Please modify the arguments for the device (device) used at the end.
For GPU training (default): device=0
For multiple GPUs: device=0,1
For M1 or M2 chips: device=mps
Below are common arguments:
- model: The training model used
- data: The training dataset
- epoch: The number of iterations (training) in machine learning training
4. Overfitting in Machine Learning
Patience in machine learning training typically refers to a technique used for early stopping control, especially when monitoring model performance. Early stopping is a technique to prevent overfitting, allowing training to stop early when the model's performance on the validation dataset no longer improves, thus saving computational resources and maintaining the model's generalizability.
Specifically, patience refers to stopping training when there is no significant improvement in the model's performance over a certain number of consecutive iterations. This number is usually a hyperparameter that you can set during the training process. Training will stop prematurely if there is no improvement in the model's performance over a number of iterations specified by patience.
For instance, suppose you set patience to 5, this means if the model's performance does not improve over 5 consecutive iterations, then training will stop. This helps avoid overfitting, as continuing training once the model's performance on the validation dataset no longer improves might lead to the model overfitting the training data.
The value of patience should be adjusted based on the specific task and data, typically determined through experimentation and monitoring of model performance. A larger patience value means the model will have more opportunities for performance improvement but might also result in longer training times. A smaller patience value might cause the model to stop prematurely, so it needs to be chosen carefully.
To explain the concept of overfitting (overfitting) mentioned above, we can use an example from everyday life:
Imagine you are learning how to drive a car, and you plan to take a driving test to obtain your driver's license. You decide to practice driving, so you go to an empty parking lot filled with orange traffic cones. You begin practicing, trying to maneuver flexibly between these cones.
At first, you might drive very cautiously, trying to maintain equal distances between each cone. However, as time goes by and you practice repeatedly in this parking lot, you become very skilled. At this point, you might become overconfident, start to drive faster, and may begin to ignore the positions of the cones.
This is an example of overfitting:
-
Adapting to Training Data: Initially, your driving behavior is influenced by your training data (the cones in the parking lot). You learn how to drive between these cones, just like a model learns to make predictions on training data.
-
Overconfidence: Over time, you become overconfident, thinking you can drive without considering the cones. This is like a model performing well on training data but failing to generalize to new data.
-
Loss of Generalization Ability: When you encounter different road conditions or traffic situations in your driving test, you might fail to adapt because you have overfitted to the specific scenario of the parking lot. This is like a model performing poorly on new data because it has overfitted the training data and fails to adapt to new situations.
In machine learning, overfitting refers to the phenomenon where a model performs well on training data but poorly on new data. To avoid overfitting, we often need to use regularization techniques, more training data, or choose simpler models to ensure the model can generalize better to new data.
Having explained these terms, your model should be almost done training by now. The training process is as follows, and is saved to run/detect/train.

As for the explanation of the model data, I will write a separate detailed article about it later, so I won't elaborate further here.
After opening the 'train' folder, you can see the following files:
You can see the weights and visualized data, such as the confusion matrix, PR curve, etc.
5. Final Steps and Future Plans
Note: If you find the training taking too long, you can also use Google Colab's T4 GPU for training (the training speed is leagues ahead of the M1 chip, I always use this for model training because I can't afford a T4 graphics card).
That concludes today's content. The next chapter is planned to explain how to label unclassified data (Labeling), and I hope today's content has been helpful to everyone.